
Insurance companies have seen a tremendous shift in modernization. Traditionally known for the use of legacy systems, leading carriers are modernizing their infrastructure by moving to the cloud and embracing new technologies, such as AI, all with the goal of maintaining profitable growth.
A common leading practice for those companies that have yielded value on innovation has been the ability to go to market with new digital products quickly, automate manual processes, and connect with customers, and their data, wherever they are. The main areas where this is true are:
- Connected Insurance & Mobility
The rise of IoT and telematics means insurers are changing product offerings, and ways of doing business. Think about the competitive advantage that leading companies (Progressive) had being the first to launch a telematics product. It comes with the advantage of having more accurate pricing and, as a result, cultivating a customer base that is more willing to share data if it results in better premiums for them. - Decision Support & Automation
Decision support and automated processing can both lower Total Cost of Ownership (TCO), as well as enable new digital products, and deliver real-time customer experiences. This trend is affecting some of the most mature areas of the insurance value chain, such as underwriting, where companies try to maximize Straight Through Processing (STP) to triage policies so that underwriters only look at the most complex risks to determine acceptability and eligibility. - New Products, Better Experiences
Digital platforms and partners connect consumers with claim adjusters and partners for increased consumer insight. Connected cars, homes, and mobile devices enable immediate and enriched FNOL (first notice of loss). Also, a better customer experience breeds loyalty, with digital platforms becoming effective portals to upsell and cross-sell new products.
Challenges (Operation vs Analytics)
Personal lines (auto, home owners, renters) are an area of insurance where insurers have a wealth of data about their customers. In many cases, such as with personal auto these businesses are becoming more competitive with many competitors in the space. As a result, insurers are looking to differentiate themselves in a commoditizing business. With pricing pressure, AI/ML is emerging as a way to maximize profits by turning data into insights and actioning them to better price insurance, automate processes, and target products to customers. But incorporating AI/ML into the insurance process is hard to do well.
One of the biggest challenges in bringing machine learning to existing business workflows is the skills required to span two types of teams that are traditionally in entirely different organizations. You need data scientists and data engineers who know the data, and where a model can be pointed to for training, and you need software developers, people who know where in the application landscape you can intercept these manual decisions, and who know how to write the complex code needed to weave data and insights into an existing application.
Furthermore, to be data driven, companies must stitch disparate systems and rely on AI-driven applications to get real-time data and make decisions faster. However, these AI-driven applications have multiple challenges when they are needed to be taken into production:
- Operational and analytical needs
Applications are often built with multiple operational data platforms; analytics and AI often require multiple analytical data platforms; AI-driven apps can be the worst of both worlds. - Real-time requirements
Companies struggle to get the latest, freshest (real-time) data while minimizing curation and copying data for analysis in the data warehouse. - Data is complicated
Companies struggle to efficiently leverage real-world data both structured and unstructured – and often require complex processing.
Opportunities
Out of this complexity, there is an opportunity to simplify operation and analytics needs, manage real-time needs, and simplify data management, by leveraging best of breed operational and analytics platforms for insurance use cases.
When brought together, MongoDB and Databricks bring the simplicity and real-time data and analytics management insurers need to scale AI across the organization.
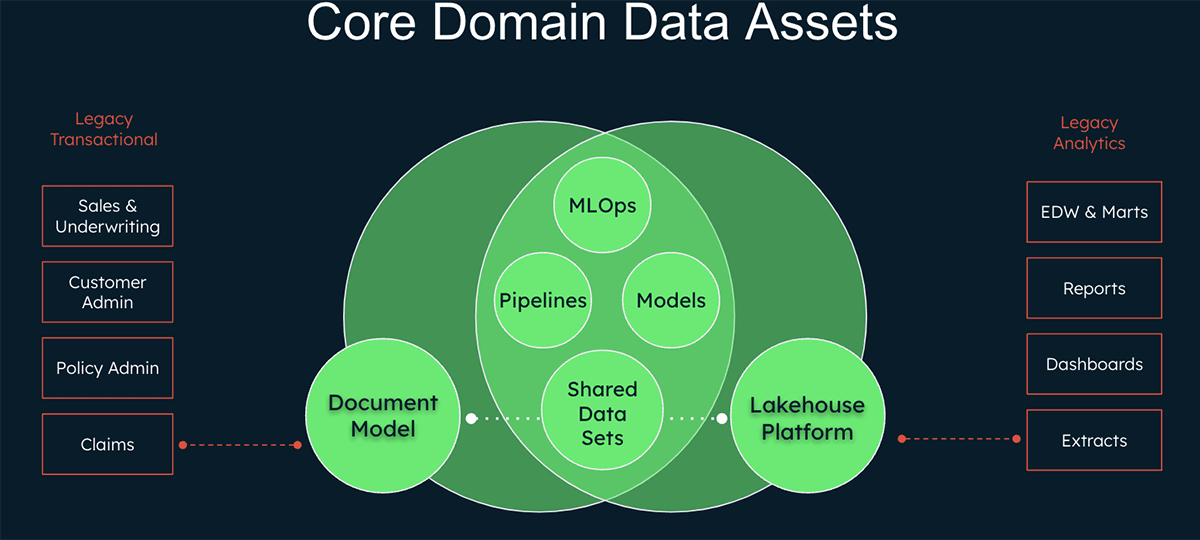
Transactional/operational (MongoDB)
- MongoDB Atlas is the only multi-cloud developer data platform that simplifies how you build with data
- Build better apps – faster, and with less resources
- Combines all data types and application development needs (query, search, vector search, mobile, etc.) into one developer data platform
Analytics (Databricks)
- Collaborative toolset for the Data Scientist, Data Practitioner, Data Engineers
- Gain better insight – in real time and with AI, leveraging all types of data (structured, semi-structured, unstructured)
- Combines all Machine Learning, Analytics, BI, and Streaming use cases into the Lakehouse, e.g. one analytics data platform
What happens when you combine these two technologies, bringing together the transactional and analytical worlds?
- Easily build real-time AI-driven applications
- Reduce costs and simplify architecture with integrated platforms for operational and analytical data
- Work with data in any format, evolving applications and insights rapidly
How will this work in practice (in an insurance use case)?
Leveraging the architecture, design, and build work, insurers can listen to events that stream in from their legacy systems, and into discrete microservice domains and their respective event buses. An organization that’s matured into an event-based architecture is well-suited to begin weaving in machine learning into key points in their business workflows.
MongoDB can capture events for operational purposes and store them. MongoDB Atlas is a major accelerator, because it allows software teams to move quickly, with very few people. Not only does the Document Model give you agility and flexibility, but platform features like Triggers, Functions, and Charts, let users implement what can essentially be considered a “low-code” solution. This accelerates the building of data transformation pipelines, to turn raw model output into information that could be more easily consumed by those that need to use the data. Essentially you are able to build applications to deliver real-time for your data decisioning process.
But the business impact one could generate with data will only be as good as the quantity, quality, and variety of historical data available for machine learning. Telematics data, for instance, could be aggregated into sessions (i.e. trips) on an operational platform like MongoDB and returned as-is for visualization purposes, but would need further enrichment to be used for behavioral modeling or dynamic pricing.
Enter the Databricks Lakehouse. With its native support for real time data ingestion and AI, Databricks allows data practitioners to derive further insights around driver behaviors (or change of behaviors) by combining additional risk factors, vehicle information or weather conditions.
Sample Use Case: Telematics Pricing
To demonstrate the value realized from combining the transactional and analytical world, we will now take a deep dive into one of the main drivers of innovation mentioned above, Connected Insurance & Mobility. Specifically, we will cover the use case of Telematics Pricing for Personal Auto Insurance.
As insurance companies strive to provide personalized and real-time products, the move towards sophisticated and real-time data-driven underwriting models is inevitable. To process all of this information efficiently, software delivery teams will need to become experts at building and maintaining data processing pipelines. Thifollowing example shows how insurers can revolutionize the underwriting process within your organization, by demonstrating how easy it is to create a usage-based insurance model using MongoDB and Databricks.
Take a look at this video, that shows how this telematics, usage based insurance demo works end-to-end.
Please also reference our code companion to the solution demo in our Github repository. In the GitHub repo, you will find detailed step-by-step instructions on how to build the data upload and transformation pipeline leveraging MongoDB Atlas platform features, as well as how to generate, send, and process events to and from Databricks.
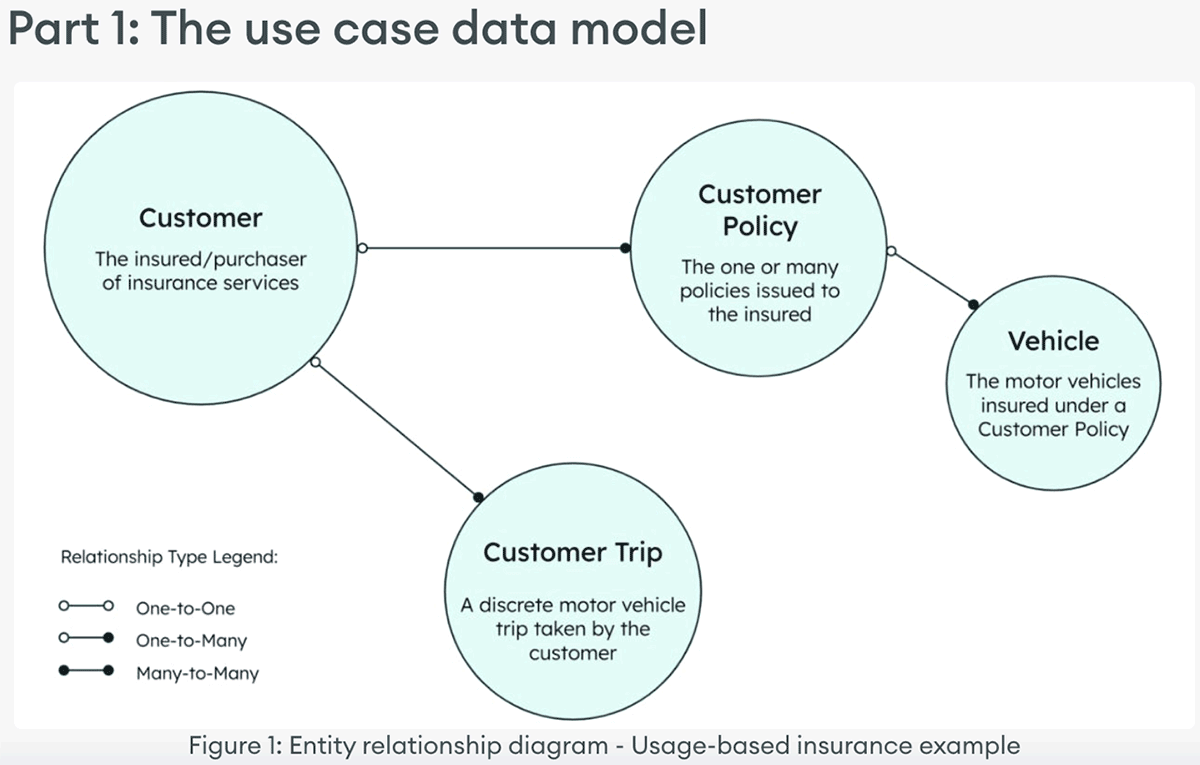
Part 1: The use case data model
Imagine being able to offer your customers personalized usage-based premiums that take into account their driving habits and behavior. To do this, you’ll need to gather data from connected vehicles, send it to a Machine Learning platform for analysis, and then use the results to create a personalized premium for your customers. You’ll also want to visualize the data to identify trends and gain insights. This unique, tailored approach will give your customers greater control over their insurance costs while helping you to provide more accurate and fair pricing.
A basic example data model to support this use case would include customers, the trips they take, the policies they purchase, and the vehicles insured by those policies.
This example builds out three MongoDB collections, as well two Materialized Views.
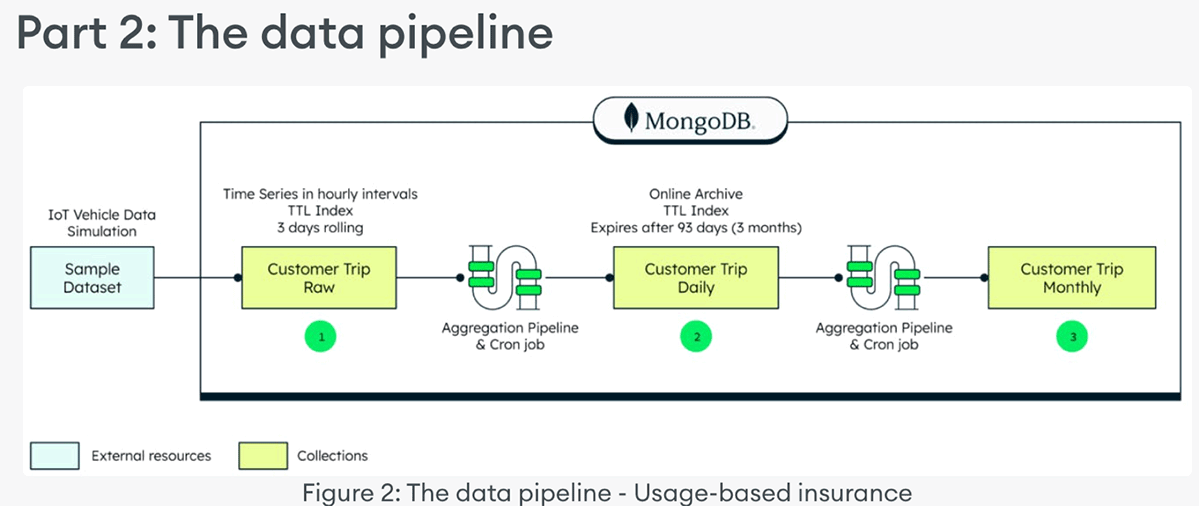
Part 2: The data pipeline
The data processing pipeline component of this example consists of sample data, a daily materialized view, and a monthly materialized view. A sample dataset of IoT vehicle telemetry data represents the motor vehicle trips taken by customers. It’s loaded into the collection named ‘customerTripRaw’. The dataset can be found here and can be loaded via MongoImport, or other methods.
To create a materialized view, a scheduled Trigger executes a function that runs an Aggregation Pipeline. This then generates a daily summary of the raw IoT data, and lands that in a Materialized View collection named ‘customerTripDaily’. Similarly for a monthly materialized view, a scheduled Trigger executes a function that runs an Aggregation Pipeline that, on a monthly basis, summarizes the information in the ‘customerTripDaily’ collection, and lands that in a Materialized View collection named ‘customerTripMonthly'(3).
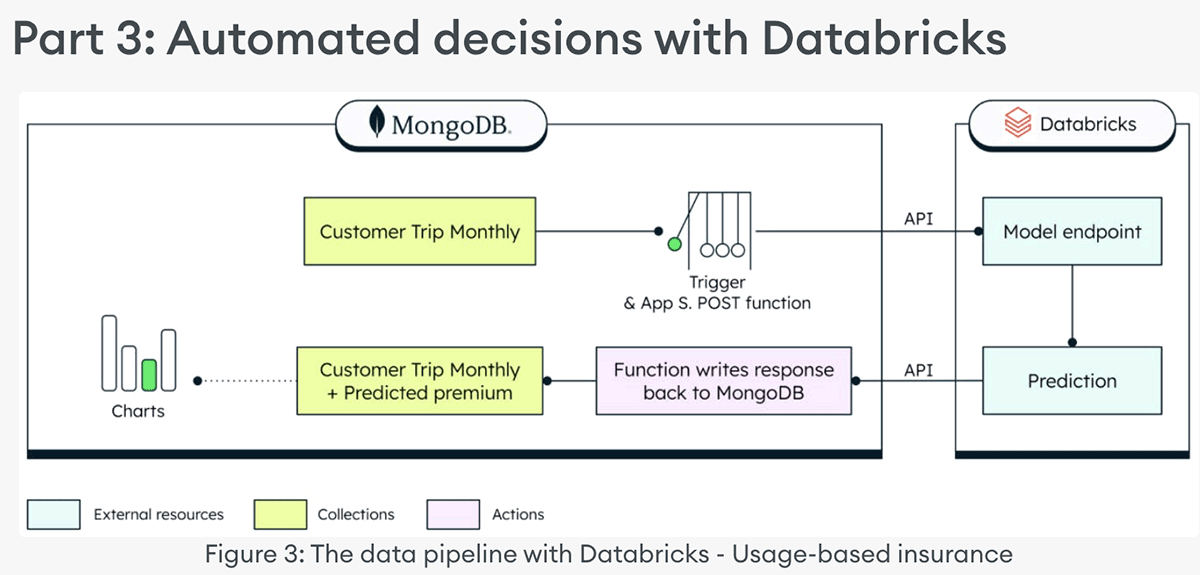
Part 3: Automated decisions with Databricks
The decision-processing component of this example consists of a scheduled trigger and an Atlas Chart. The scheduled trigger collects the necessary data and posts the payload to a Databricks ML Flow API endpoint (the model was previously trained using the MongoDB Spark Connector on Databricks). It then waits for the model to respond with a calculated premium based on the miles driven by a given customer in a month. Then the scheduled trigger updates the ‘customerPolicy’ collection, to append a new monthly premium calculation as a new subdocument within the ‘monthlyPremium’ array. You can then visualize your newly calculated usage-based premiums with an Atlas Chart!
In the GitHub repo are step-by-step instructions on how to build the data upload and transformation pipeline leveraging MongoDB Atlas platform features, as well as how to generate, send, and process events to and from Databricks.




{kind=link}