
Machine learning models have been operating for a long time on a single data mode or unimodal mode. This involved text for translation and language modeling, images for object detection and image classification, and audio for speech recognition.
However, it’s a well-known fact that human intelligence is not restricted to a single data modality as human beings are capable of reading as well as writing text. Humans are capable of seeing images and watching videos. They can be on the lookout for strange noises to detect danger and listen to music at the same time for relaxation. Hence, working with multimodal data is necessary for both humans and artificial intelligence (AI) to function in the real world.
A major headway in AI research and development is most probably the incorporation of additional modalities like image inputs into large language models (LLMs) resulting in the creation of large multimodal models (LMMs). Now, one needs to understand what exactly LMMs are as every multimodal system is not a
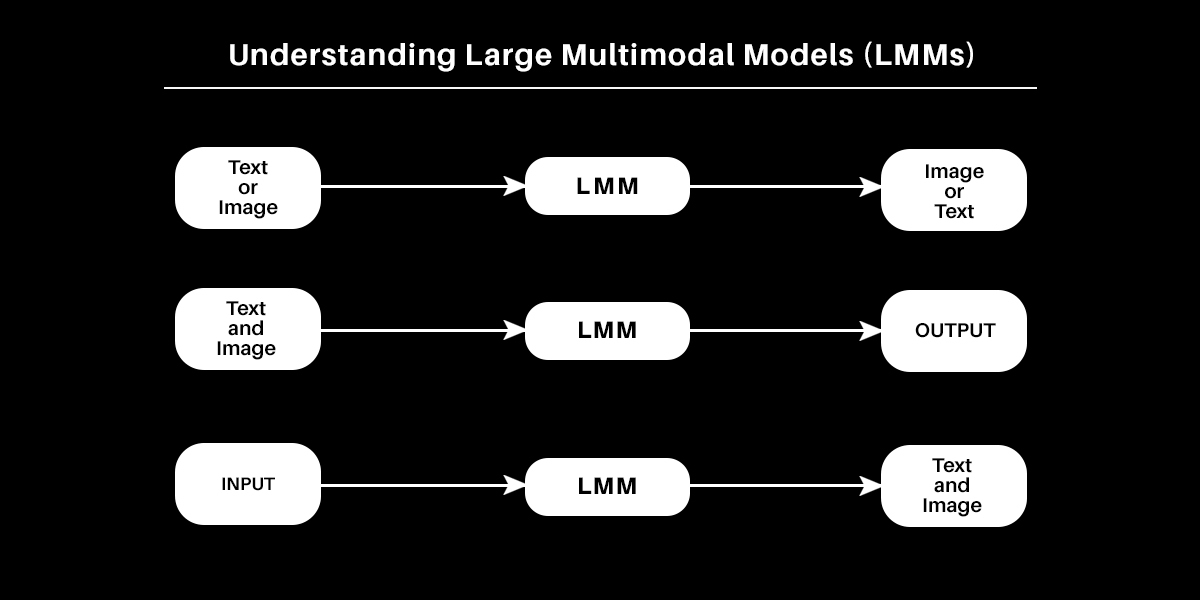
LMM. Multimodal can be any one of the following:
1. Input and output comprise of different modalities (text to image or image to text).
2. Inputs are multimodal (both text and images can be processed).
3. Outputs are multimodal (a system can produce text as well as images).
Use Cases for Large Multimodal Models
LMMs offer a flexible interface for interaction allowing one to interact with them in the best possible manner. It enables one to query by simply typing, talking, or pointing their camera at something. A specific use case worth mentioning here involves enabling blind people to browse the Internet. Several use cases are not possible without multimodality. These include industries dealing with a mix of data modalities like healthcare, robotics, e-commerce, retail, gaming, etc. Also, bringing data from other modalities can assist in boosting the performance of the model.
Even though multimodal AI isn’t something new, it is gathering momentum. It has tremendous potential for transforming human-like capabilities through development in computer vision and natural language processing. LMM is much closer to imitating human perception than ever before.
Given the technology is still in its primary stage, it is still better when compared to humans in several tests. There are several interesting applications of multimodal AI apart from just context recognition. Multimodal AI assists with business planning and utilizes machine learning algorithms since it can recognize various kinds of information and offers much better and more informed insights.
The combination of information from different streams enables it to make predictions regarding a company’s financial results and maintenance requirements. In case of old equipment not receiving the desired attention, a multimodal AI can deduce that it doesn’t require servicing frequently.
A multimodal approach can be used by AI to recognize various kinds of information. For instance, a person may understand an image through an image, while another through a video or a song. Various kinds of languages can also be recognized which can prove to be very beneficial.
A combination of image and sound can enable a human to describe an object in a manner that a computer cannot. Multimodal AI can assist in limiting that gap. Along with computer vision, multimodal systems can learn from various kinds of information. They can make decisions by recognizing texts and images from a visual image. They can also learn about them from context.
Summing up, several research projects have investigated multimodal learning enabling AI to learn from various kinds of information enabling machines to comprehend a human’s message. Earlier several organizations had concentrated their efforts on expanding their unimodal systems, but, the recent development of multimodal applications has opened doors for chip vendors and platform companies.
Multimodal systems can resolve issues that are common with traditional machine learning systems. For instance, it can incorporate text and images along with audio and video. The initial step here involves aligning the internal representation of the model across modalities.
Many organizations have embraced this technology. LMM framework derives its success based on language, audio, and vision networks. It can resolve issues in every domain at the same time by combining these technologies. As an example, Google Translate utilizes a multimodal neural network for translations which is a step in the direction of speech integration, language, and vision understanding into one network.
The post From Large Language Models to Large Multimodal Models appeared first on Datafloq.




{kind=link}