

(Gorodenkoff/Shutterstock)
Data observability refers to the ability to comprehensively monitor and understand the behavior of data within a system. It provides transparency into real-time aspects of the data pipeline beyond data monitoring. These include quality, resource usage, operational metrics, system interdependencies, data lineage, and the overall health of the data infrastructure.
In the context of data integration, the ability to monitor and understand the flow of data is key to ensuring the quality and reliability of data as it moves through various stages of the integration process. With the mainstreaming of AI-powered data integration workflows, users often raise legitimate concerns about a lack of transparency in workflows, data bias in reporting and analytics, or disagreements with results and insights.
Robust data observability practices ensure transparency across the data integration life cycle — from production to consumption — and give business users the confidence to make data-led business decisions.
Companies with high data observability standards can easily and confidently answer questions that directly impact data integration outcomes. For example:

(Best Backgrounds/Shutterstock)
- How true is the data available to business users? Are data engineers, data scientists, and business ops teams seeing and using the same data? Is our data losing fidelity during the data integration process?
- Are we able to track data lineage? Do we have a clear record of the origins, transformations, and destinations of the data as it runs through our pipelines? Can we reflect changes in data integration workflows throughout the data ecosystem?
- Do we have real-time visibility into our data processes? How will changes in one part of the pipeline affect downstream processes? Can we detect anomalies that may impact data integrity or performance in real-time?
- How effective are our root cause analysis processes? Do we have fast detection of data anomalies, bottlenecks and vulnerabilities that enable predictive maintenance and preventive actions?
- Can we troubleshoot effectively? When pipelines break, how quickly can we identify the point-of-failure, make a timely intervention and fix it?
- Are our data integration workflows in compliance? Do our processes meet data governance, security and privacy regulations?
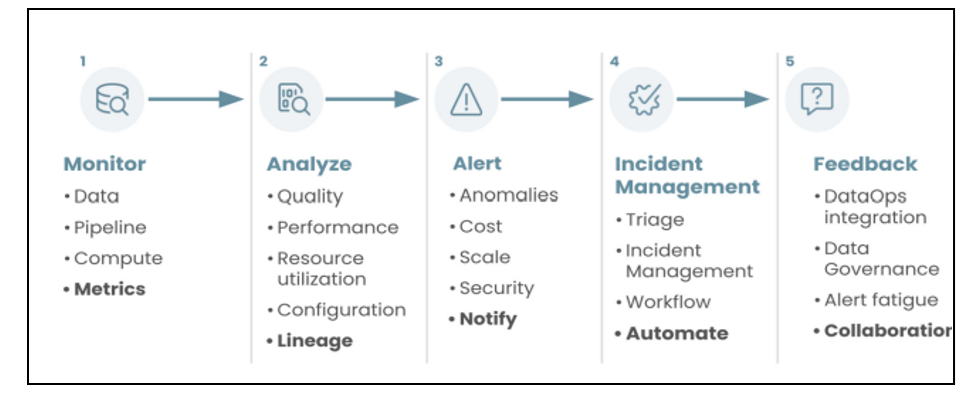
Key components of data observability (Source: Informatica)
While bottlenecks and breakages can occur even with the best of data pipelines, observability puts in place checkpoints to bring trust and credibility to the data. Ultimately, the more the business trusts and uses the data, the higher the ROI of data integration investments.
AI-Powered Data Observability
In increasingly complex, hybrid data integration environments, the need for data observability practices is more urgent than ever. However manual processes are woefully inadequate to manage these demands.
AI-driven tools improve data observability and provide real-time visibility into data pipelines by automating the monitoring, analysis, and detection of issues across workflows, no matter how large-scale and complex the operations.
Some areas where AI-driven tools make a significant impact include:
Anomaly Detection
In complex data integration environments, even identifying the point-of-failure in a pipeline can be a challenge. AI algorithms can learn the normal patterns and behaviors of data flows and flag any anomalies or deviations from those patterns. Modern AI-powered data observability tools help reduce the mean-time-to-detect (MTTD) and meantime-to-resolve (MTTR) data quality and pipeline problems.
Predictive Analytics
Machine learning models help predict future trends or issues based on historical data patterns. This visibility helps predict potential bottlenecks, latency issues, or errors in data integration processes, allowing for proactive optimization and ongoing process improvement.
Automated Root-Cause Analysis
AI can analyze extensive data and system logs to identify the root causes of issues automatically. Pinpointing the source of errors or discrepancies reduces the time to detection and system downtime. Less need for reactive troubleshooting also translates into improved resource utilization and operational cost efficiency.
Analysis of Manual Logs and Documentation
Over the years, a lot of documentation around data integration workflows piles up across the organization in inconsistent formats and diverse locations. AI-powered Natural Language Processing (NLP) techniques can understand, process and interpret logs, documentation, and communication related to data integration, and extract meaningful insights to detect issues or identify areas for improvement.
Data Quality Monitoring
Machine learning models can be trained to monitor data for accuracy and completeness and automatically flag and address data quality issues as they arise, often without any human intervention
Automated Metadata Management
AI-driven tools can automate the collection, tagging, and organization of metadata related to data integration processes. Data catalogs make it easier to search for and track data lineage, dependencies, and other critical information related to data integration, promoting better data discovery and understanding.

(Panchenko Vladimir/Shutterstock)
Make Data Observability Integral to Your Modern Data Integration Strategy
Data observability, a notable innovation in the Gartner Hyper Cycle 2022, is fast attracting the attention of future-ready data engineers.
The resulting explosion in the number of observability solutions in the market has led to a fragmentation of capabilities, with many products defining data observability too narrowly, offering only a subset of the required capabilities, or adding to the complexity of the data integration ecosystem.
A comprehensive observability solution should offer end-to-end visibility, as well as advanced anomaly detection, predictive analytics, and automated issue resolution capabilities that work seamlessly across multi-cloud and hybrid cloud environments.
However, this should not make life more complicated for data engineers, who already have to manage and monitor diverse and complex data pipelines.
To address this, modern data integration solutions are increasingly embedding advanced observability capabilities into the core product, which further streamlines operations across the entire data supply chain.
AI-powered, end-to-end data management and integration solutions can help you work smarter at each stage of the data integration workflow while leveraging the benefits of advanced data observability capabilities to reduce errors, manage costs and generate more value from your data.
About the author: Sudipta Datta is a data enthusiast and a veteran product marketing manager. She has a rich experience with data storage, data backup, messaging queue, data hub and data integration solutions in different companies like IBM and Informatica. She enjoys explaining complex, technical and theoretical ideas in simple terms and helping customers understand what’s in it for them.
marketing manager. She has a rich experience with data storage, data backup, messaging queue, data hub and data integration solutions in different companies like IBM and Informatica. She enjoys explaining complex, technical and theoretical ideas in simple terms and helping customers understand what’s in it for them.
Related Items:
Data Observability ROI: 5 Key Areas to Construct a Compelling Business Case
There Are Four Types of Data Observability. Which One is Right for You?
Observability Primed for a Breakout 2023: Prediction




{kind=link}